Qwen2.5: Alibaba's Latest Open-Source Series of Large Models
By Horay AI Team|
Introduction
On September 19, 2024, three months after the release of Qwen, the team has absorbed valuable feedback from various developers and, through relentless efforts, brought a new member to this family: Qwen2.5. This could potentially be the largest open-source series of models ever.
What is Qwen2.5?
Qwen is a series of large language models and multimodal models developed by the Qwen team at Alibaba Group. Among them, Qwen2.5 is the new version in its large language model series. Qwen 2.5 is an open-source artificial intelligence language model with powerful text generation and understanding capabilities, supporting multiple languages and applicable to various natural language processing tasks. Users can customize it according to specific needs, widely applied in content creation, customer service, education, and other fields, promoting the widespread application of artificial intelligence technology.
In this release, the Qwen team announced the open-source large language model Qwen2.5, as well as specialized models for programming, Qwen2.5-Coder, and for mathematics, Qwen2.5-Math. All open-weight models are decoder-only language models, available in various sizes, including:
- Qwen2.5: 0.5B, 1.5B, 3B, 7B, 14B, 32B, and 72B
- Qwen2.5-Coder: 1.5B, 7B, and 32B on the way
- Qwen2.5-Math: 1.5B, 7B, and 72B.
Additionally, they provide APIs for the flagship language models Qwen2.5-Plus and Qwen2.5-Turbo through Model Studio, helping everyone quickly develop or integrate generative AI capabilities.
For more detailed information about Qwen2.5, Qwen2.5-Coder, and Qwen2.5-Math, please visit the official website.
Performance
Qwen2.5
According to the Qwen team, all models in Qwen2.5 are pre-trained on the latest large-scale databases, containing up to 18 trillion tokens, and are fine-tuned with high-quality data to align with human preferences.
Compared to Qwen2, Qwen2.5 not only boasts a larger knowledge capacity but also sees significant improvements in coding and mathematical capabilities. When compared to several leading proprietary and open-source large models, the new model has made notable strides in following instructions, generating long texts, understanding structured data, and producing structured outputs, especially in JSON format. The Qwen2.5 model is generally more resilient when faced with diverse system prompts, enhancing the realization of role-playing and the setup of chatbots. Like Qwen2, the Qwen2.5 language model supports up to 128K tokens and can generate up to 8K tokens. They also maintain multi-language support for over 29 languages, including Chinese, English, French, Spanish, Portuguese, German, Italian, Russian, Japanese, Korean, Vietnamese, Thai, Arabic, and more. Below is the basic information about the models and detailed information on supported languages.
Benchmark results of Qwen2.5-72B instruct against leading open-source models Llama-3.1-70B, Mistral-Large-V2, and DeepSeek-V2.5.
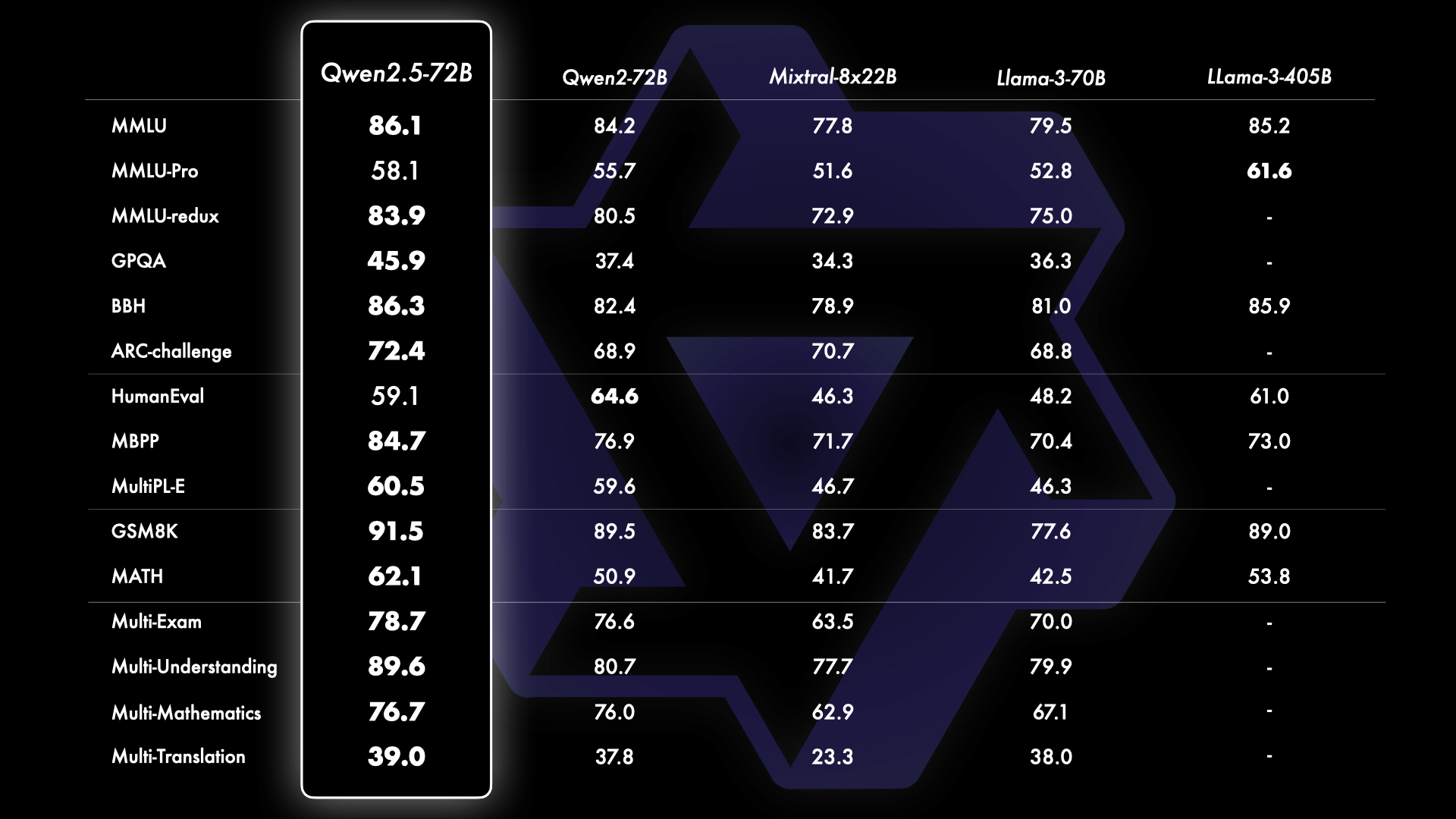
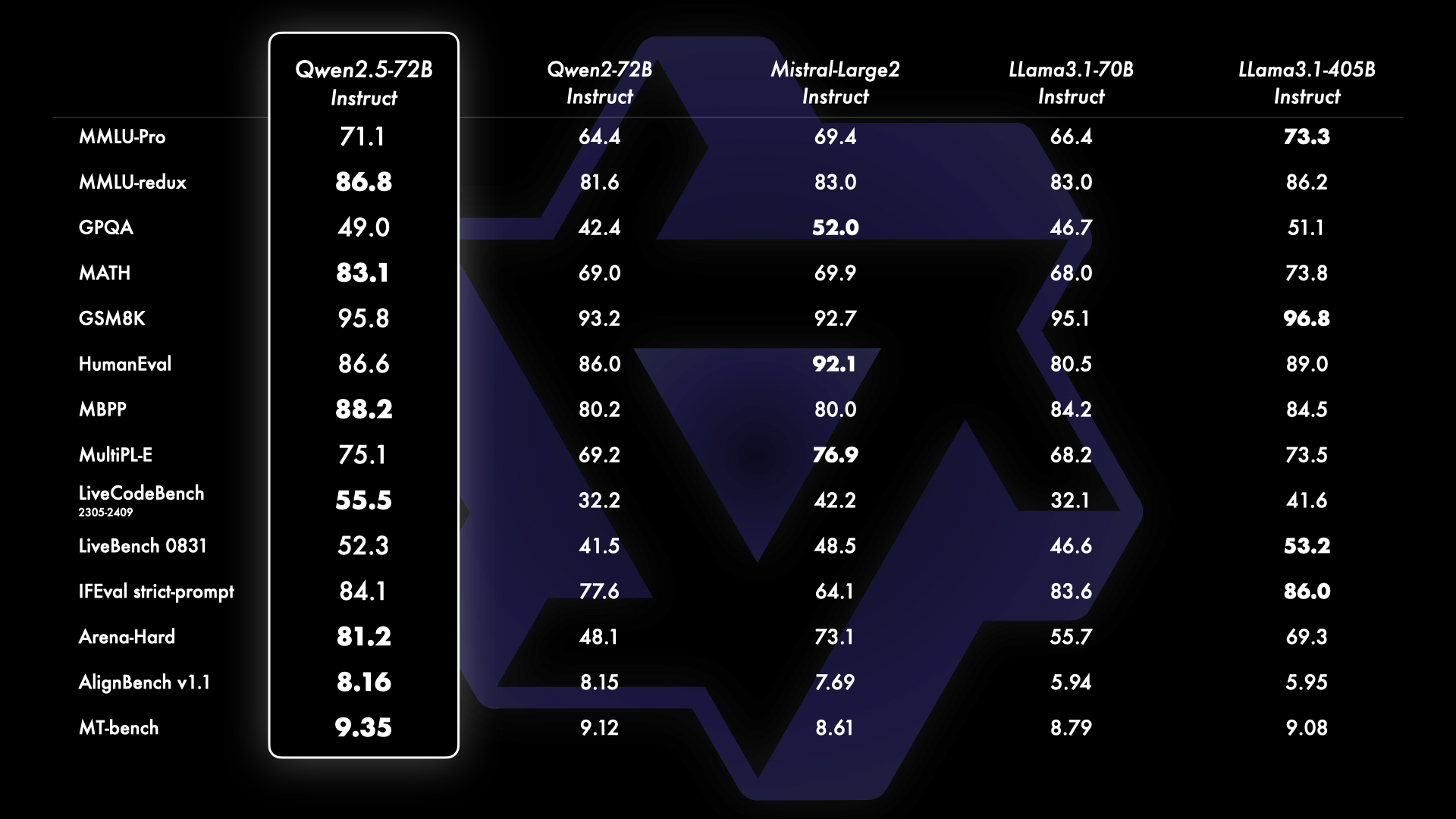
Benchmark results of the flagship open-source model Qwen2.5-72B instruct leading open-source models Qwen2-72B, Mistral-8×22B, Llama-3-70B, and Llama-3-405B.
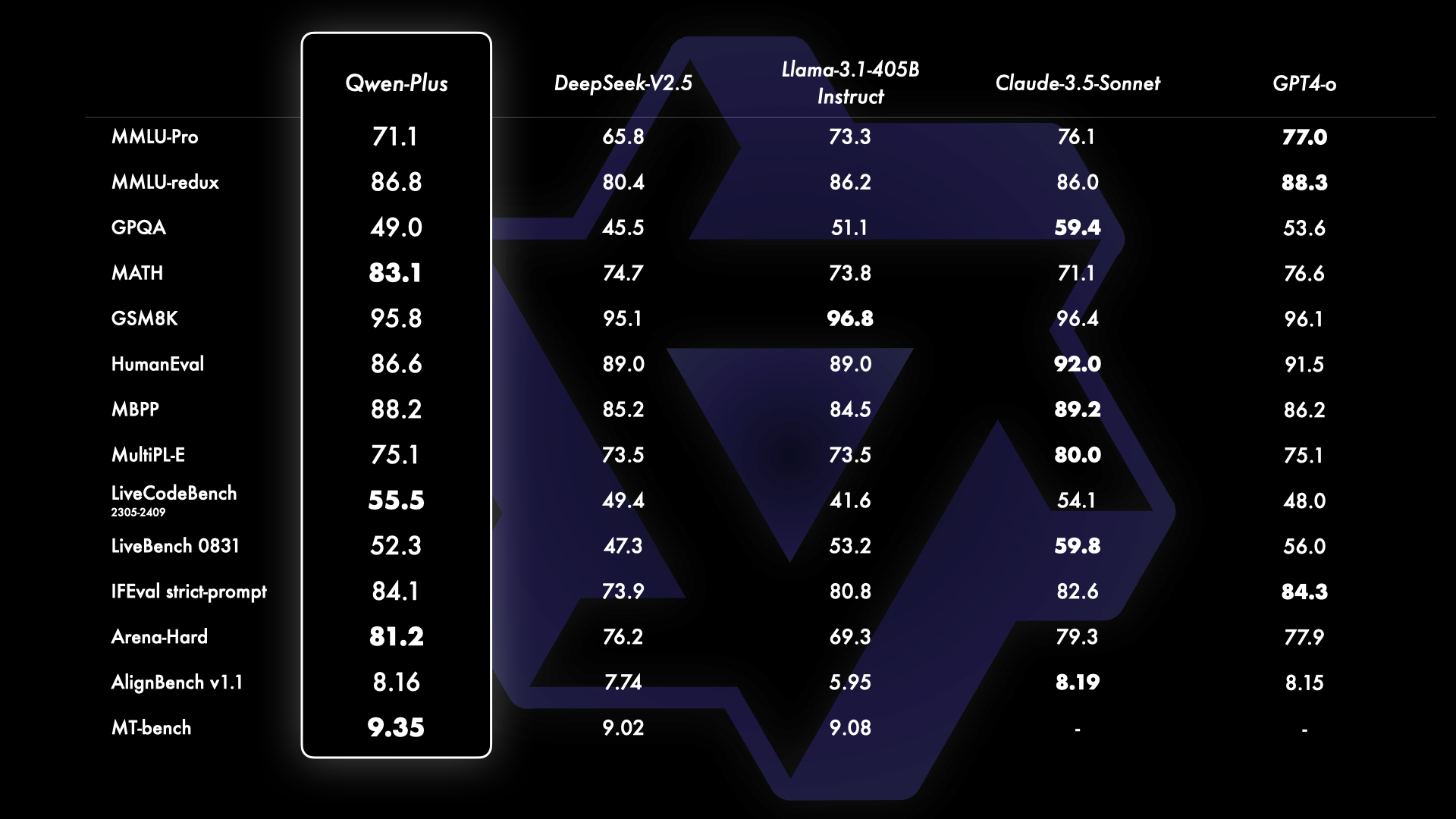
Comparison of the API-based model Qwen-Plus with leading proprietary and open-source models, including GPT4-o, Claude-3.5-Sonnet, Llama-3.1-405B, and DeepSeek-V2.5.
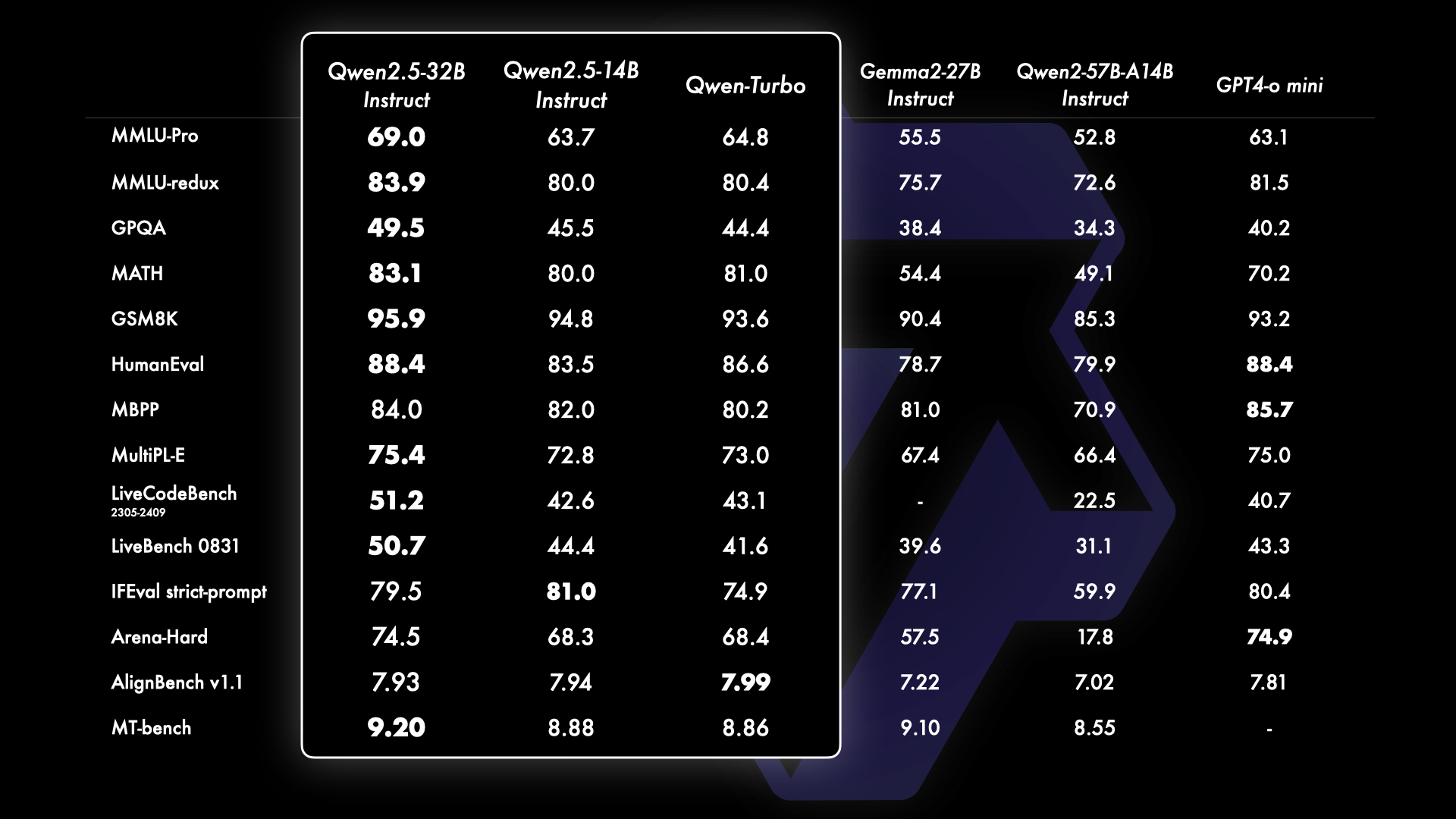
Comparison of Qwen2.5-14B, Qwen2.5-32B, and Qwen-Turbo with Gemma2-27B-IT, Qwen2-57B-A148-IT, and GPT-4o mini.
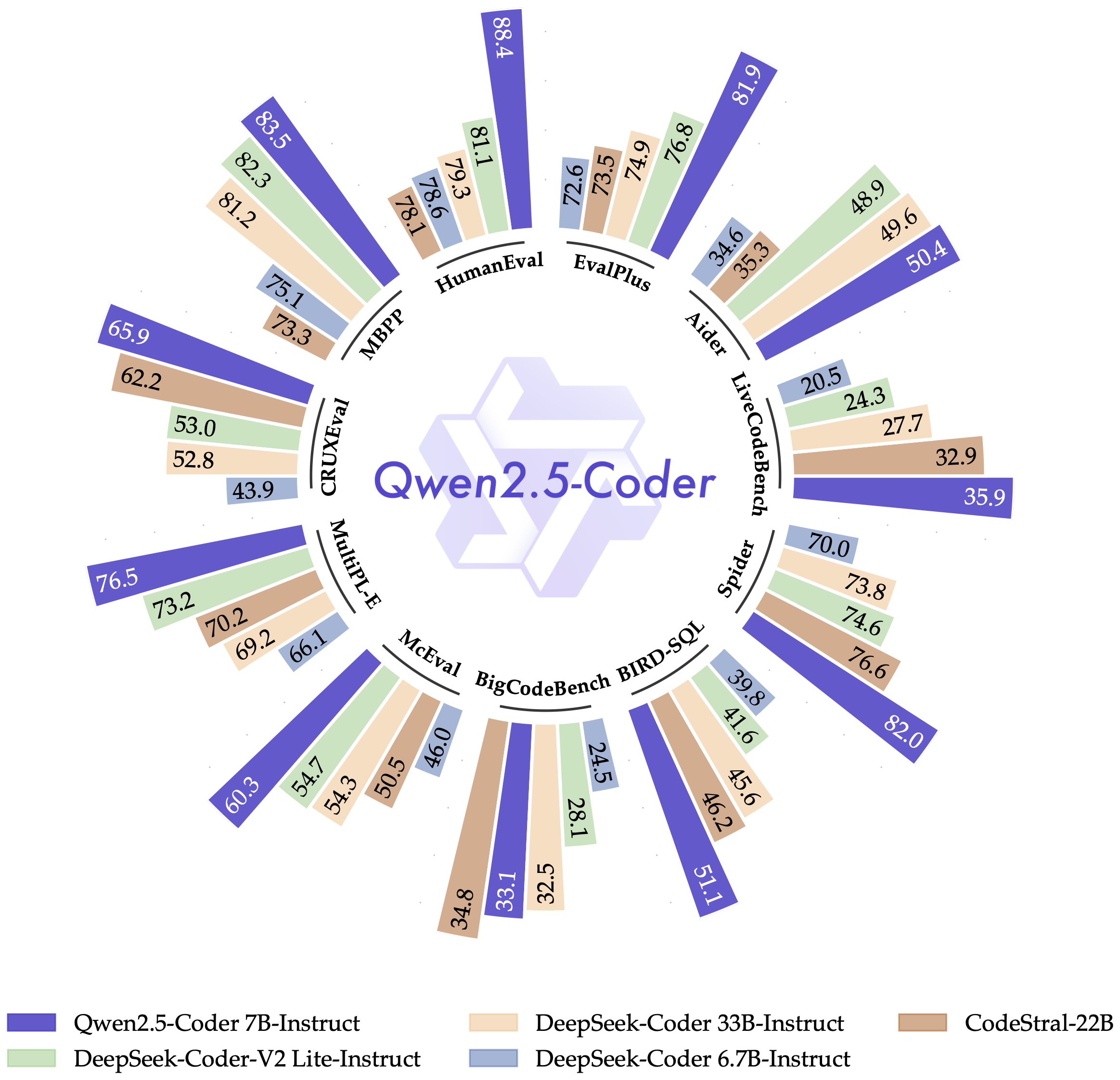
Qwen2.5-Coder
The latest version from the Qwen team, Qwen2.5-Coder, is specifically designed for programming applications. The chart below shows the performance results of Qwen2.5-Coder-7B-Instruct, benchmarked against leading open-source models with significantly larger parameters. As the chart indicates, the model demonstrates remarkable effectiveness across various aspects, showcasing excellent programming capabilities in multiple programming languages and tasks, making it an excellent choice for personal programming assistants.
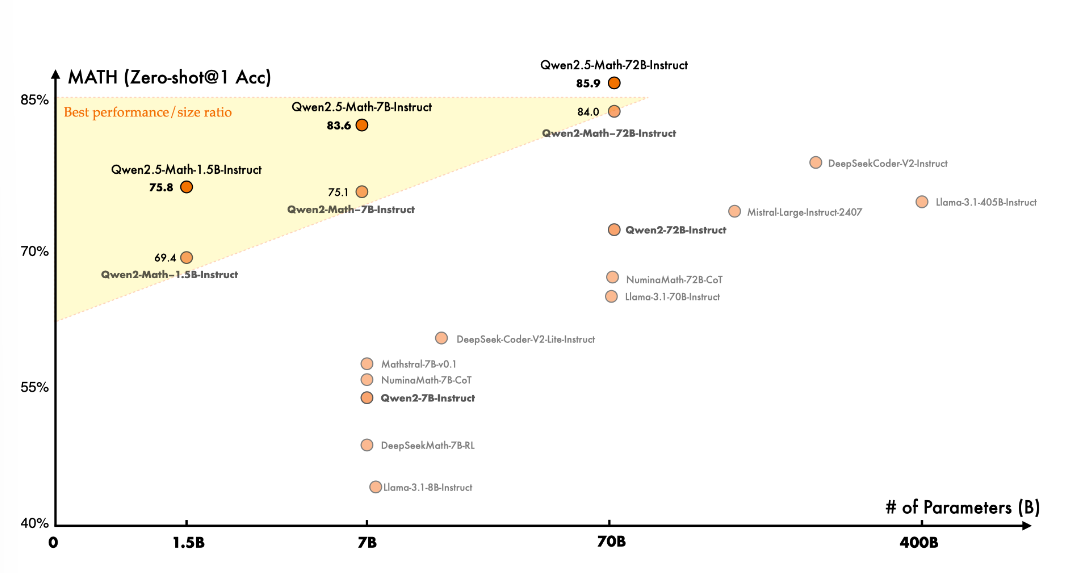
Qwen2.5-Math
Qwen-2.5-Math, in the realm of mathematical specific language models, has been pre-trained on larger-scale data and expanded support for Chinese, enhancing its reasoning capabilities.
Features of Qwen2.5
- 1. Open-Source Release: Qwen 2.5 is potentially the largest open-source release in history, including various language models such as Qwen 2.5, Qwen 2.5-Coder, and Qwen 2.5-Math, all available in multiple parameter sizes.
- 2. Enhanced Performance: Qwen 2.5 excels in multiple benchmarks, significantly increasing its knowledge capacity (MMLU score of 85+) compared to Qwen 2, and showing marked improvements in coding (HumanEval 85+) and mathematical (MATH 80+) abilities.
- 3. Long Text Generation: The model supports generating texts up to 8K in length and can better understand and generate structured data, especially in JSON format.
- 4. Multi-Language Support: Supports over 29 languages, including Chinese, English, French, etc., catering to global needs.
- 5. Specialized Models: Introduces models specifically tailored for coding and mathematics, Qwen 2.5-Coder and Qwen 2.5-Math. The former is trained on 5.5 trillion code-related data, while the latter enhances reasoning capabilities, supporting Chain-of-Thought, Program-of-Thought, and Tool-Integrated Reasoning methods.
- 6. Flexibility and Ease of Use: All open-weight models are provided under license on Hugging Face, facilitating user integration and usage.
- 7. Competitiveness of Small Models: Even small models (like Qwen 2.5-3B) compete with large models in performance, showcasing high knowledge density and efficiency.
How to Use Qwen2.5?
- 1. Open Source Version:
- a. Hugging Face Qwen 2.5 Collection: https://huggingface.co/collections/Qwen/qwen25-66e81a666513e518adb90d9e
- b. GitHub: https://github.com/QwenLM/Qwen2.5
- c. Demo: https://huggingface.co/spaces/Qwen/Qwen2.5
- 2. The Horay platform is set to launch a free Qwen 2.5 series model with enhanced inference acceleration. Plus, sign up now and get $5 credit to explore a variety of accelerated models. Check it out: https://www.horay.ai/